
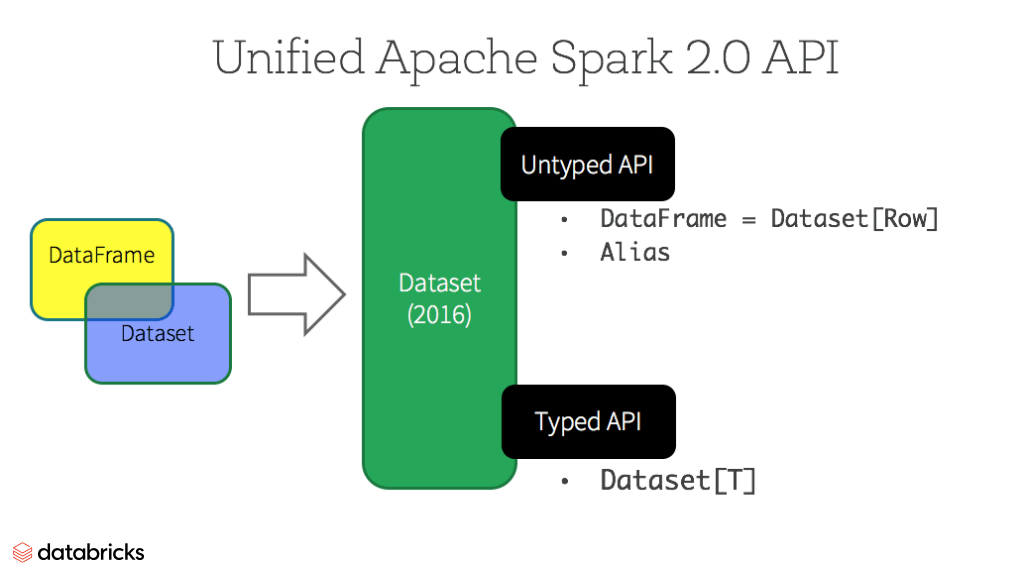
DataFrame and Dataset
History
- DataFrame since Spark 1.3
- Dataset since Spark 1.6 (preview)
- Unified since Spark 2.0 (type DataFrame = Dataset[Row])
- Scala Type Alias: https://alvinalexander.com/scala/scala-type-aliases-syntax-examples
- DataFrames and Datasets are built on top of RDDs.

DataFrame
- RDD + Schema (named column, type) => RDBMS Table 처럼
- Untyped API
- a Row is a generic untyped JVM object.
- type DataFrame = Dataset[Row]
- df.select($“name”).where($“age > 30”) 처럼 DF는 column name을 가지고 column을 지칭. type check는 runtime에
- sparkSession.sql(“select name from …”)
- a Row is a generic untyped JVM object.
Dataset
- Dataset is a collection of strongly-typed JVM objects, dictated by a case class you define in Scala or a class in Java.
- Dataset[명시적_Value_Object]
- Typed API
- ds.filter(.age > 30).map(.name) 처럼 DS는 case class의 attribute로 column을 지칭. type check가 compile time에 가능
- 개발 시점에 query의 오류를 잡아낼 수 있다. (column type mismatch, non-existing column name, …) 개발자의 시간은 소중하니까!
성능 관련
- Dataset, Dataframe은 Schema를 가지고 있기 때문에 RDD에 비해 높은 성능 최적화를 수행
- 모두 실은 Dataset이고, 동일한 optimization / execution engine 사용
- Catalyst - Query Optimizer
- Tungsten - Execution Engine (like compiler, including a bytecode gen)
- 모두 실은 Dataset이고, 동일한 optimization / execution engine 사용
DataSet / Frame은 어떻게 Filter pushdown을 하게 될까?
- p81: “SQL 옵티마이저와 달리 DAG 옵티마이저는 연산 순서를 재정렬하거나 필터를 푸시다운하는 능력이 없기 때문에 코어 스파크에서는 연산 순서의 고려가 더욱 중요하다.
- https://databricks-prod-cloudfront.cloud.databricks.com/public/4027ec902e239c93eaaa8714f173bcfc/3741049972324885/4201913720573284/4413065072037724/latest.html
질의 옵티마이저
- Catalyst
- Spark SQL 질의 옵티마이저. 질의계획을 받아서 실행 계획으로 변환
- 논리적 계획 -> 물리적 계획 -> 코드 생성
- 논리적 계획
- DataFrame이나 DataSet에 Transformation 적용할 때의 질의 계획을 Tree Graph로 생성
- 트리에 패턴 매칭을 적용하여 단순화
- 물리적 계획
- 규칙 기반 최적화
- 비용 기반 최적화
- Datasource 계층까지의 Predicate Pushdown : >, <, >= 등의 비교식을 통해 데이터 범위 좁혀감
- 코드 생성
- 실행 계획을 Java 바이트 코드로 생성
- Janino 사용 (https://git.io/vpGGs)
- 논리적 계획
- 디버깅
- spark.sql().explain
- df.printSchema
- Spark SQL filter pushdown 확인 가능